



我们的操作系统需要运行各种各样程序,为了程序的管理,进行了各种各样的抽象,对内存的管理,抽象了虚拟内存,对程序抽象出了进程。随着cpu核心的增多,进程的抽象有点笨重,主要原因是
- 创建进程的开销比较大,父子进程之间需要拷贝的东西比较多,虽然为解决内存共享的一些问题,提出了写时拷贝技术,但是写时拷贝会造成延时
- 进程之间通信的开销高,共享数据和同步数据比较麻烦
于是又抽象在进程里面抽象了线程的概念,现在操作系统的最小的资源管理单位变成了进程,cup最小的执行单位变成线程。我们可以看下面的示意图
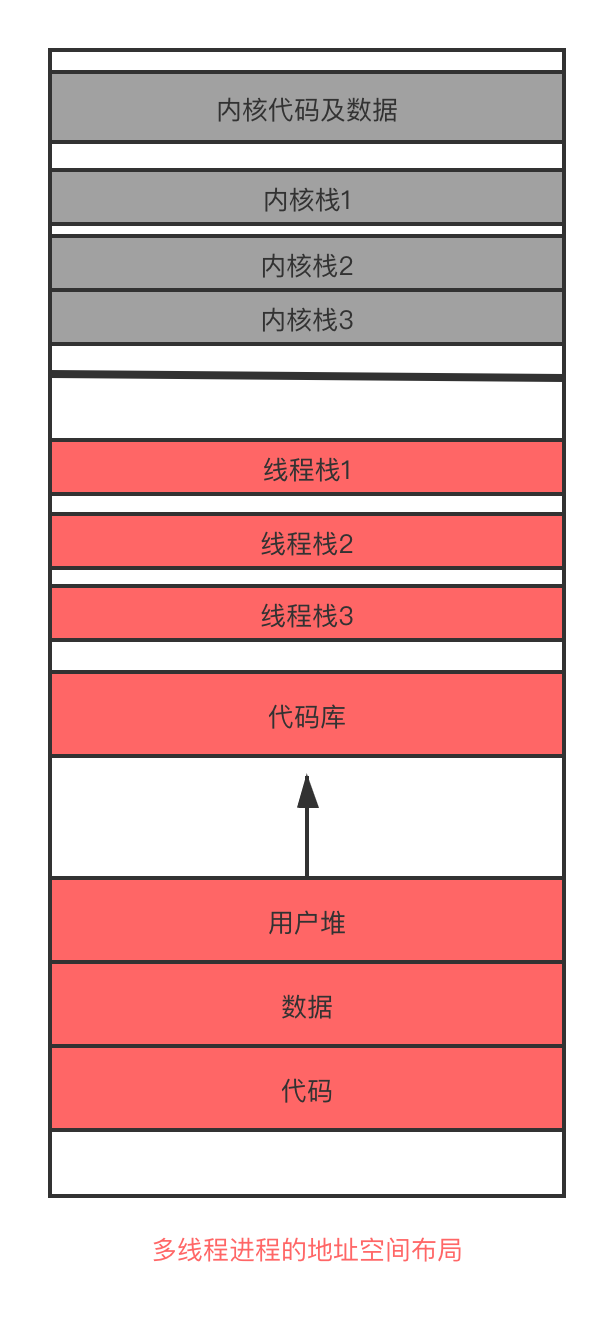
上图的线程栈和内核栈是一对一的关系。这里说明一下,根据线程是由用户态应用还是内核创建与管理,可将线程分为两类:用户态线程与内核态线程。内核态线程由内核创建,受操作系统调度器直接管理。而用户态线程则是应用自己创建的,内核不可见,因此不受系统调度器直接管理。与内核相关的操作需要内核态线程协助才能完成。上述图片,内核线程与用户态线程是一对一关系(Windows 和Linux 采用的是一对一模型),也就是每个用户态线程映射单独的内核态线程。
由于主流的操作系统采用的一对一的线程模型,用户态线程几乎完全受到操作系统调度器的管理。可是我们的程序变得越来越复杂,如视频播放中,有线程复杂网络通信,有线程复杂帧的组包,有线程复杂解码,有线程负责与gpu通信渲染画面。在这种情况下,应用程序对线程的执行会更加了解,在调度上可以做出更优的决策,而且用户态线程更加轻量化,比内核线程的创建和切换的开销低。面对这种情况,操作系统又提供了更多的用户态线程,即纤程(fiber)。那么用户态线程和内核态线程扩展到多对一关系。
纤程的需求:(生产者和消费者)
生产者和消费者模型包含两个部分:生产者和消费者。生产者负责生产数据,消费者负责消费数据。如果一个进程拥有两个线程,一个线程是生产者,一个线程是消费者。由于两个线程共享同一地址空间,生产者在共享的内存中生产数据,当数据生产到阈值之后,消费者消费数据。cpu上运行多个运用程序,生产者生产数据的时候,消费者线程会挂起状态,切换到消费者线程苏醒,需要内核线程上下文切换,但是调度器不一定优先调度消费者线程,这个时候消费者消费数据会有延迟,这个不受应用程序控制。原因是操作系统通过中断的方式抢占cup,进行上下文切换,这种切换方式是强制的。在执行完生产者线程之后,也许会执行其他进程的线程,然后再执行该进程的消费者线程。但是在纤程中,由于是用户态线程,不能由操作系统调度,当生产者纤程执行完,该消费者执行,那么通过合作的方式通知消费者,纤程库提供yield接口,暂时放弃cpu,保存当前上下文,执行消费者纤程,实现更好的调度。
由于不涉及到内核线程与用户态线程上下文的切换,执行速度会变快。纤程概念在编程语言层面的实现叫协程。
async await
javascript语言在es2017中规范中也引入了纤程的概念,虽然上javascript的执行是单线程,async await 会保存函数执行的上下文,当获取到执行结果的时候,再恢复对应的函数上下文进行执行。纤程的思想也被引入了前端框架React ,利用纤程的概念来协调,进行有序,可控的调度,将大量的js运算时间间隔执行,来让浏览器有时间渲染页面,减少过多组件的的同时变动导致的页面卡顿,不流畅。
发表评论