


垃圾回收的运行会阻断渲染进程的运行,这会影响浏览器的体验。V8引擎的开发者打算优化v8的垃圾回收模块,优化的垃圾收集器代号为Orinoco。Orinoco与之前未优化的垃圾回收器相比
- 实现一个主要是并行和并发的垃圾收集器
- 模糊代际边界(主要是新生代对象和老生代对象)
- 减少了垃圾收集的时间和内存消耗,并提高了垃圾回收的吞吐量
在这篇文章中我们讨论新的垃圾收集器的三个特性,他们分别是
- 并行compaction
- 并行记忆集处理
- 黑色分配
V8实现了代际垃圾收集器,新生代对象在经历两次回收生存下来的对象会被划分到老生代对象存储空间。对象在内存中移动的代价是很昂贵的,主要是在引擎中我们需要对象的需要复制到新的位置,此外我们还需要更新这些对象的指针。图1显示了Orinoco之前的阶段及其执行方式。基本上,对象先被移动,之后再更新这些对象之间的指针,所有这些都是按顺序进行的,消耗的时间过长。

V8将其堆内存分割成固定大小的块,这些称为页,将他们分为新生代和老生代。新建的对象被分配在新生代,当进行垃圾收集时,活着的对象在年轻一代中移动一次。在第二次圾收集中幸存下来的对象被分配到老生代。对于这两个阶段,我们统称为幼代疏散,我们将内存的复制基于页并行。在年轻一代中,移动对象总是涉及到在新页上分配内存(并释放旧页),留下一个紧凑的内存布局。在老一代中,这个过程的发生方式略有不同,因为死的内存会留下无法使用的洞(或碎片)。其中一些洞可以通过自由列表重用,但另一些洞则被留下,需要压实来将活的对象移动到一个更好的打包(可能是新的)页面。与年轻一代类似,这个过程也是在页级上并行的。
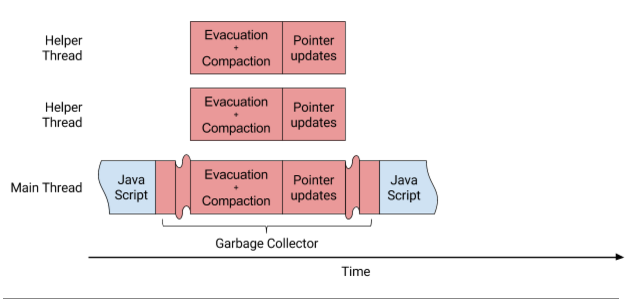
由于年轻一代的疏散和老一代的压实之间没有依赖关系,Orinoco现在并行执行这些阶段,如图2所示。这些改进的结果是将压实时间减少了75%,从平均约7ms减少到2ms以下。
Orinoco引入的第二个优化改进了垃圾收集器跟踪指针的方式。当一个对象在堆上移动位置时,垃圾收集器必须找到所有包含移动对象旧位置的指针,并以新位置更新它们。由于在堆中迭代查找指针会非常慢,所以V8使用了一个叫做记忆集的数据结构来跟踪堆上所有有趣的指针。如果一个指针指向一个可能在垃圾收集过程中移动的对象,那么这个指针就是有趣的。例如,所有从旧一代到新一代的指针都是有趣的,因为新一代的对象在每次垃圾收集时都会移动。指向严重碎片化页面中的对象的指针也很有趣,因为这些对象会在压实过程中移动到其他页面。
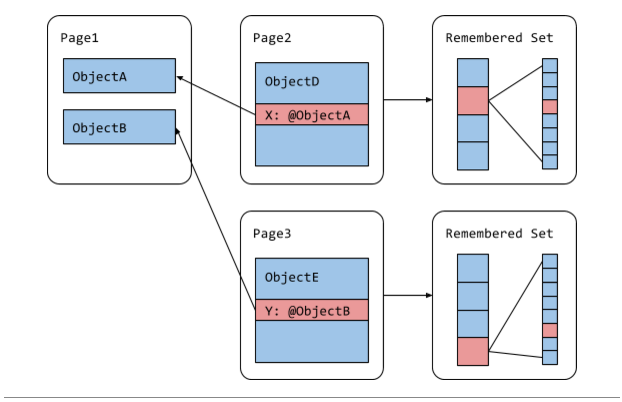
以前,V8将记忆集实现为指针地址的数组,或存储缓冲区。年轻一代有一个存储缓冲区,碎片化的老一代页面各有一个存储缓冲区。一个页面的存储缓冲区包含所有进入的指针的地址,如图3所示。条目被附加到存储缓冲区的写屏障中,它守护着JavaScript代码中的写操作。这可能会导致重复条目,因为一个存储缓冲区可能会多次包含一个指针,两个不同的存储缓冲区可能会包含同一个指针。重复条目使指针更新阶段的并行化变得困难,因为两个线程试图更新同一个指针而引起的数据竞赛。

Orinoco通过重新组织记忆集来消除这种复杂性,以简化并行化,并确保线程得到不相干的指针集来更新。现在每个页面不再将传入的有趣指针存储在一个数组中,而是将源自该页面的有趣指针的偏移量存储在位图的桶中,如图4所示。每个桶要么是空的,要么指向一个固定长度的位图。位图中的一个位对应于页面中的一个指针偏移。如果一个位被设置,那么这个指针就很有趣,并且在记忆集中。利用这种数据结构,我们可以根据指针更新的情况进行并行处理
使用这种数据结构,我们可以基于页面来并行更新指针。没有重复的条目和指针的密集表示,也使我们能够删除处理记忆集溢出的复杂代码。在我们长期运行的 Gmail 基准中,这一变化将压缩垃圾收集的最大暂停时间减少了 45%,从 42ms 减少到 23 ms。
Orinoco引入的第三个优化是黑色分配,是对垃圾收集器标记阶段的改进。黑色分配(在V8 5.1中发货)是一种垃圾收集技术,在这种技术中,所有在老一代中分配的对象(例如,预先租用的分配或由垃圾收集器推广的对象)都立即被标记为黑色,以指定它们为 “活”。黑色分配背后的直觉是,在旧一代中分配的对象很可能是长寿的。因此,最近在老一代中分配的对象至少应该在下一个老一代的垃圾收集器中存活下来,否则它们被虚假地推广了。将新分配的对象着色为黑色后,垃圾收集器将不会访问它们。我们通过在黑色页面上分配对象来加快对黑色对象的着色,在黑色页面上,所有对象默认都是黑色的。黑色页面的另一个好处是它们不需要被扫除,因为所有分配在它们上的对象(根据定义)都是活的。黑色分配加快了增量标记的进度,因为标记工作不会随着新的分配而增加。黑色分配的影响在Octane Splay基准上清晰可见,由于更快的标记进度和更少的垃圾收集工作,吞吐量和延迟得分提高了约30%,而使用的内存减少了约20%。
发表评论