
示意图
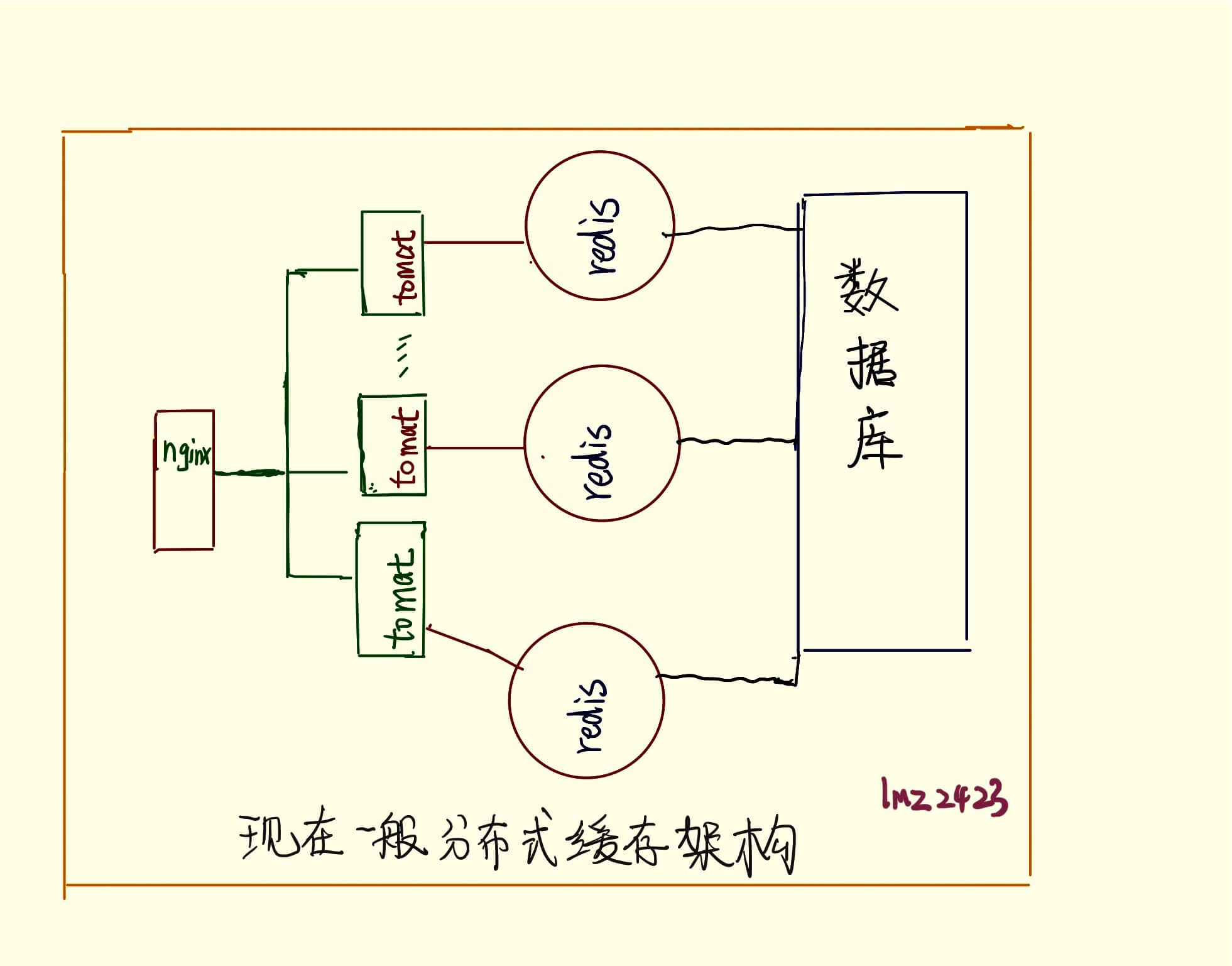
上一篇文章,我利用redis缓存来减轻数据库的压力,但是我这仍然是个在同一台服务器,开了redis缓存服务。在现在那些高并发的下,并保证高可用性的环境下,基本会将redis服务部署在不同机器上,当并发过多的时候,单点的redis服务很难保证高可用性,假如机器宕机,那么怎么办?假如缓存数量上亿计,查询对应的缓存列表也会耗时,这样也会导致延迟。这个时候很容易想到我们设置多台缓存服务器,当一台缓存服务器宕机的时候,然后请求发到没有宕机的缓存服务器上,但是又碰到了一个问题,我们怎么将请求打在对应缓存服务器中,假如同一个请求过来一次,请求的还是上一次请求的缓存服务器。
hash(request) mod n
很容易想到利用hash(request) mode n n为缓存服务器的数量 结果值为 0, 1, 2 … n-1 r 如下图所示
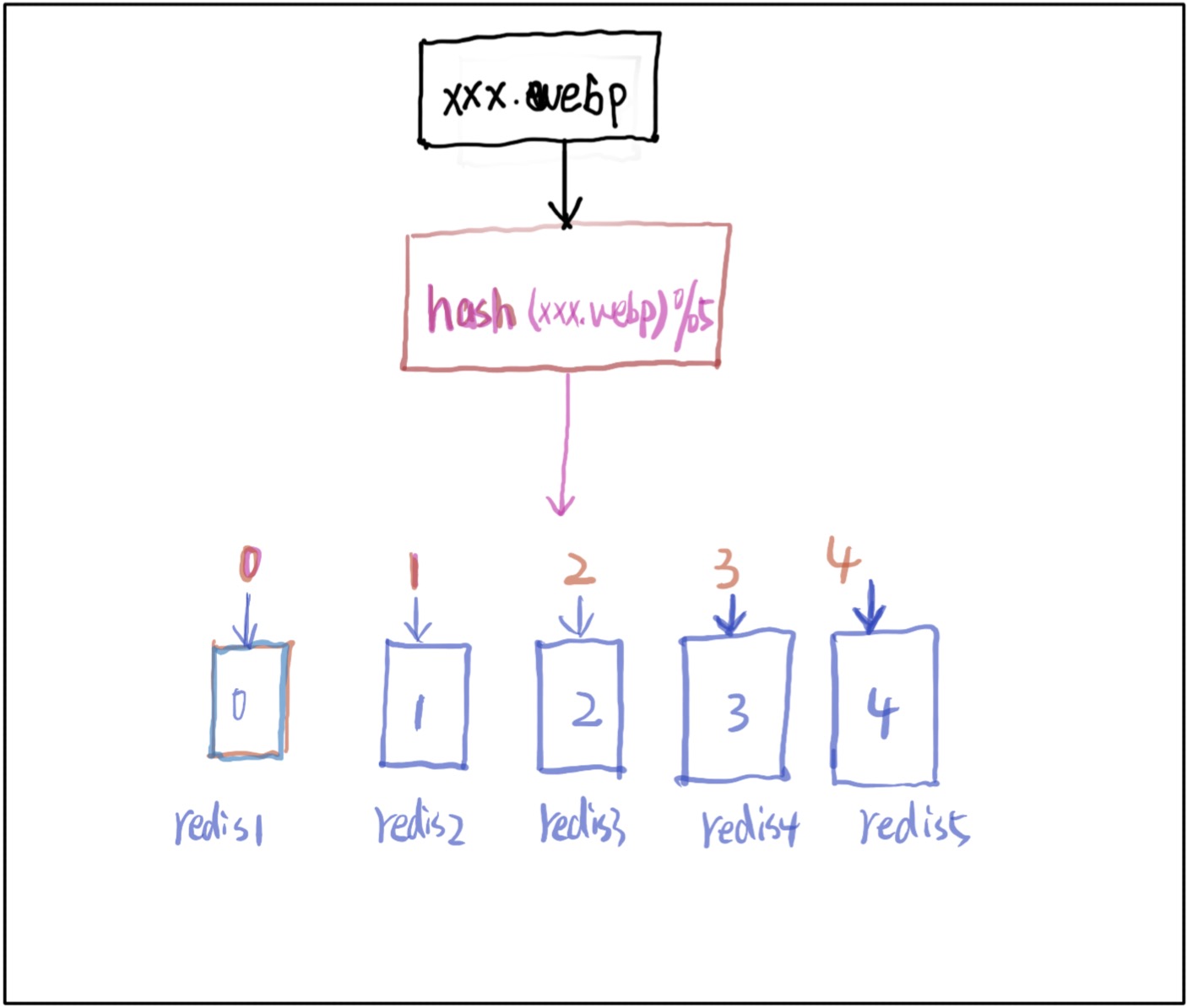
hash mod n 分配资源
这种算法有个问题,假如我们的并发量增加,我们需要增加redis缓存服务,来提高性能,或者是我们的一台缓存服务器宕机了,从5台变成了4台 ,就拿上面的5台缓存服务器的第2台缓存服务器挂了。我们用上面的算法 hash(xxx) mod 4, 我写一个模拟代码
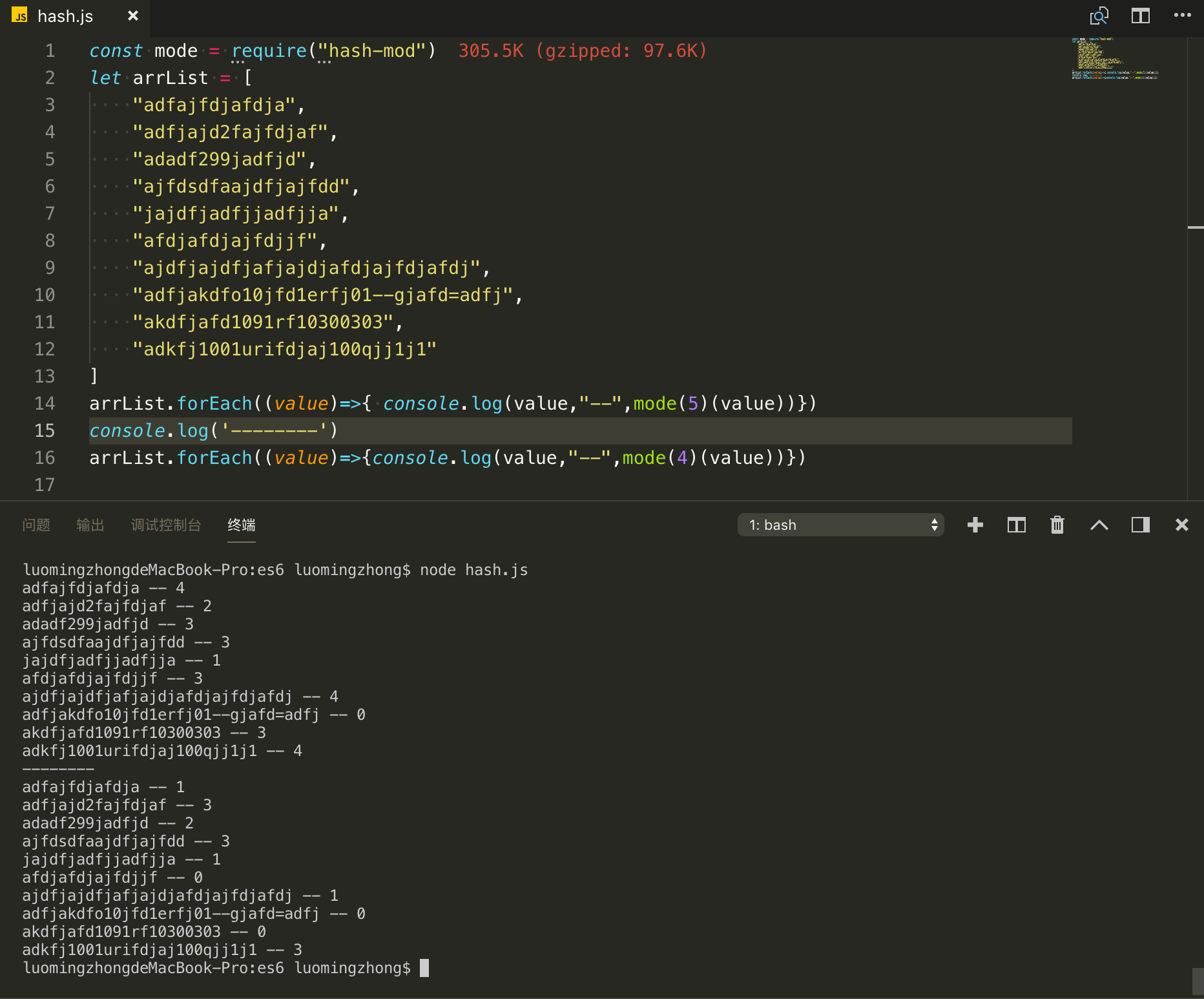
测试hash(xx) mod n
如果一台缓存服务挂掉的时候我们的缓存命中率从 100% 变成 30%。这个时候,如果有大量的并发过来,会导致数据库访问过高,产生性能瓶颈。
一致性hash算法
面对上述的情况,我们的分布式缓存算法无法能解决上述问题,这个时候一致性hash算法来解决这个问题。待续 ,要睡觉了
发表评论