
 在前一篇文章中,我们只是瞎扯一下垃圾回收。对垃圾回收的中的三大算法,标记-清除,引用计数,GC复制算法,并没有进行详细地描述。在论述这三大算法之前,我们先扯一扯GC中的基本概念,搞清楚基本概念,对理解垃圾回收算法就会容易一些。当然GC本来就是一个比较复杂的东西。
在前一篇文章中,我们只是瞎扯一下垃圾回收。对垃圾回收的中的三大算法,标记-清除,引用计数,GC复制算法,并没有进行详细地描述。在论述这三大算法之前,我们先扯一扯GC中的基本概念,搞清楚基本概念,对理解垃圾回收算法就会容易一些。当然GC本来就是一个比较复杂的东西。
我们先看下面的一张图
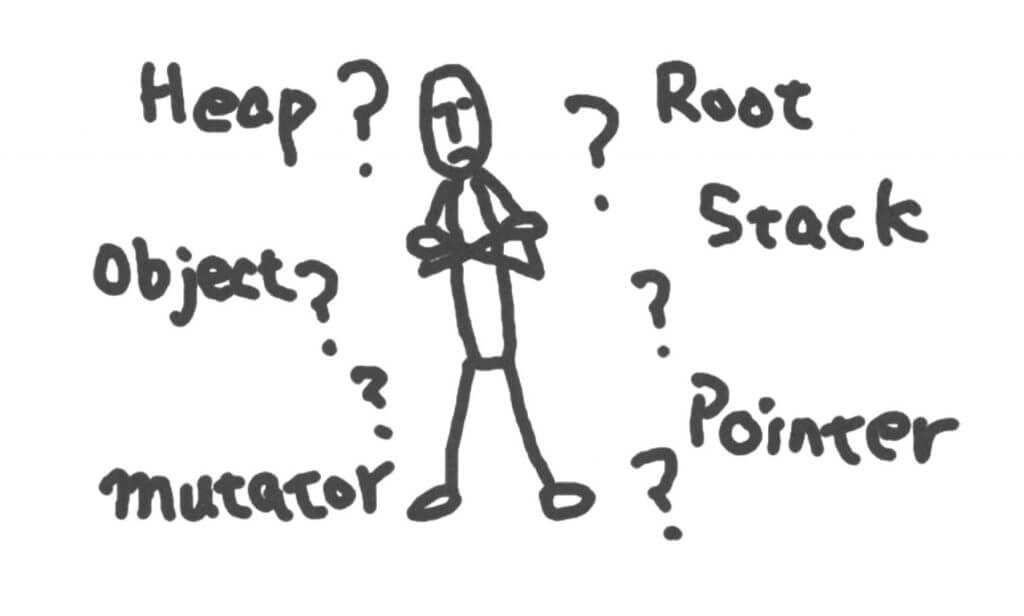
在GC中,对应上图的,分别是 Heap(堆),Object(对象)Mutator(突变体),Stack(栈),Pointer(指针),Root(根)。
对象
对象在面向对象编程中,意味着“具有属性和行为的食物”,但是在GC的世界中,对象说的是“通过应用程序利用的数据的集合”。 对象配置在内存空间里。GC根据情况将配置好的对象进行移动或销毁操作。对象是GC的基本单位。对象一般由头(header)和域(field)构成。
头
我们将对象中保存对象本身信息的部分称为“头”,头主要含有下面的信息
- 对象的大小
- 对象的种类
如果不清楚对象的大小和种类,那么就会发生问题,例如无法知道内存中存储对象的边界。头中存有运行GC的需要的信息,根据算法不同,信息也不同。对于标记-清除算法,是在对象的头部中设置1个flag来记录对象是否已标记,从而管理各个对象。
域
把对象使用者在对象中可访问的部分称为“域”。我们把域想象成C语言中的结构体的成员。对象使用者会引用或替换对象的阈值。此外,对象使用者基本上无法直接更改头的信息。
域中的数据类型大致分为2种。
- 指针
- 非指针
指针是指向内存空间中某块区域的值。即使像java,javascript这样的没有使用指针的编程语言,语言处理程序内部也用到指针。非指针指的是在编程中直接使用值本身。数值,字符以及真假值都是非指针。
对象的结构是
对象 = 对象头+域1+域2
指针
通过GC,对象会被保留或销毁,在这过程中起关键作用的是指针。GC是根据对象的指针指向去搜寻其他对象的。在大部分语言处理程序中,指针都默认指向对象的首地址(指针如果不指向对象首地址,GC会变得很复杂)我们在实现算法的时候,对象和指针的关系如下
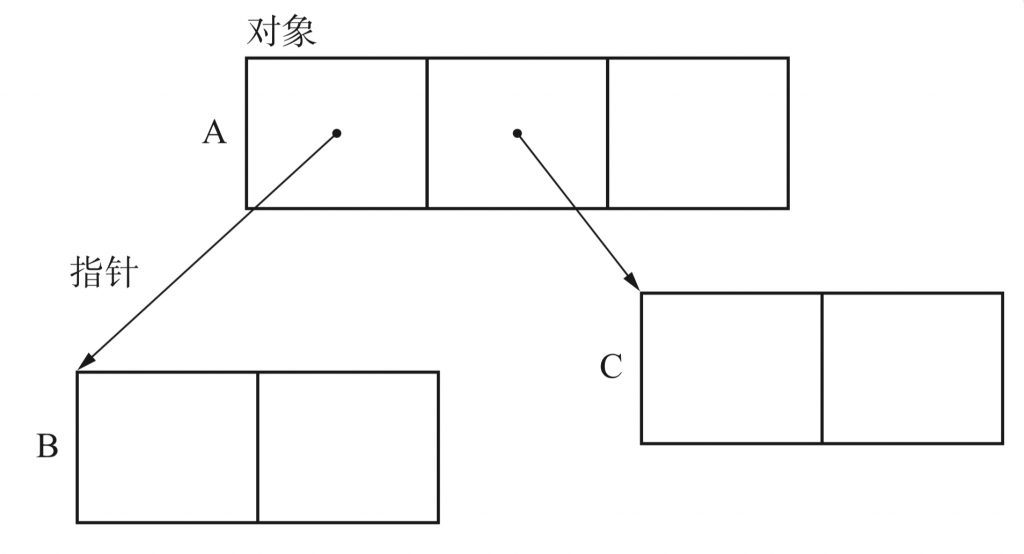
我们把b,c称为对象A的子对象。对对象的子对象进行处理是GC的基本操作。
Mutator(突变体)
对象是由谁生成呢,我们一般会说是由程序生成的。mutator这个词是由Edsger Dijkstra 提出来的,意思就是改变某个东西。mutator改变的是GC对象的引用关系。我们一般说来把Mutator说成应用程序。
mutator实际上进行的操作有两种
- 生成对象
- 更新指针
mutator在上述的操作的时候,同时为应用程序的用户进行一些处理(数值计算,浏览网页,编辑文章等)。随着这些处理的推进,对象间的引用关系也会“改变”。在这个过程中就会产生垃圾,而负责回收这些垃圾的机制就是GC
堆
堆指的是用于动态存放对象的空间。当mutator申请存放对象时,所需的内存空间就会从堆中分配给mutator.GC是管理堆中已分配对象的机制。一旦开始执行mutator,程序就会按照mutaor的要求在堆中存放对象。等到堆被对象占满后,GC就会启动,从而分配可用空间。如果不能分配可用空间,这个时候,我们就要扩大堆的空间。
活动对象/非活动对象
分配到内存空间中的对象中那些能通过mutator引用的对象称为“活动对象”。反过来,把分配到堆中那些不能通过程序引用的对象称为“非活动对象”。 这些非活用对象,我们称为垃圾,就是需要清除掉。当销毁非活动对象时,这些非活动对象占用的空间会得到解放,供下一个要分配的新对象使用。
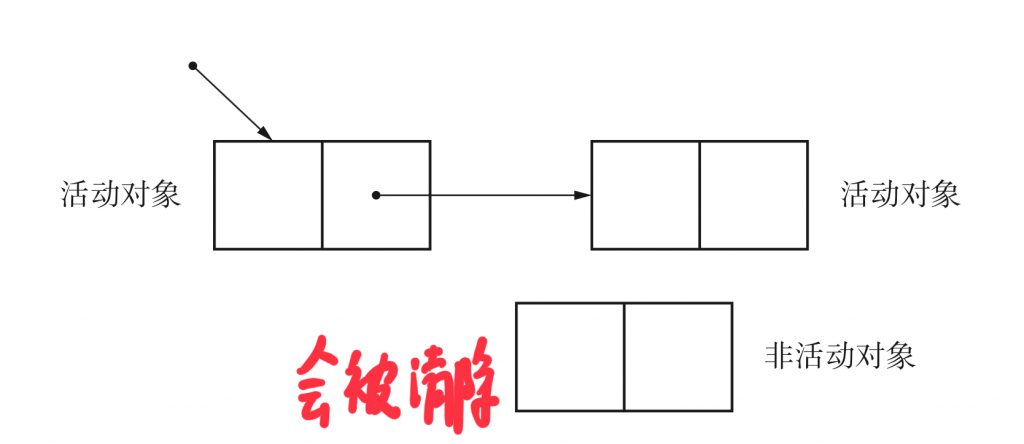
当mutator需要新对象时,就会向分配器申请一个大小合适的空间。分配器则在堆空间中寻找满足要求的空间,返回给mutator. 有GC机制的语言,在生成实例的时,会内部自动分配空间。对于没有GC机制的语言如C/C++ ,这个时候程序员需要使用malloc() 和new 运算符进行手动分配。
当堆被所有活动对象占满时,这个时候运行GC也无法分配可用空间。这个时候,一般采用如下两种选择
- 销毁至今为止的所有计算结果,输出错误信息
- 扩大堆,分配可以空间。
一般在堆情况没有特殊限制的情况下,我们是扩大堆。
根(root)
在GC的世界里,根是指向对象的指针的“起点”部分。这些都是能通过mutator直接引用的空间。我们看下面的伪代码
$obj = Object.new //对象A
$obj.field1 = Object.new //对象B$obj是全局变量。我们在第一行分配一个对象A,然后把$obj指向这个对象的指针。在第2行我们分配一个对象B,把$obj.field1指向对象B的指针。 在执行完之后,全局变量空间和堆如下图所示

我们可以使用$obj直接从伪代码中引用对象A,这样A是活动对象。可以通过$obj >对象A>对象B. 那么对象B也是活动对象。GC就需要保护这些对象不被销毁掉。
GC把上述这样直接或间接从全局变量空间中引用的对象视为活动对象。与全局变量空间相同,我们也可以通过mutator直接引用调用栈(call stack)和寄存器。那么,调用栈,寄存器以及全局变量空间都是根。
GC算法的评价标准
- 吞吐量
- 最大暂停时间
- 堆使用效率
- 访问的局部性
吞吐量
吞吐量(throughout)指的是“在单位时间内的处理能力”。我们看下面的图
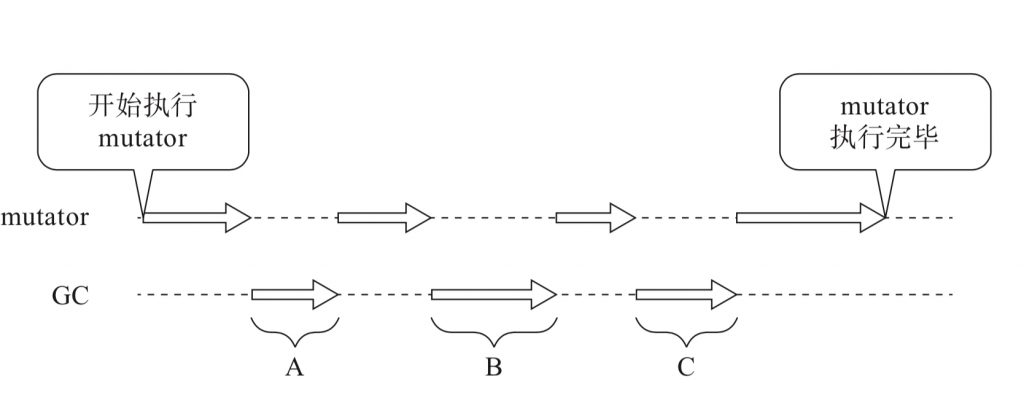
在mutator执行的过程中,GC一共启动了3次,我们把花费的时间分别设为A,B,C.也就是说GC总共花费的时间为(A+B+C)。另一方面,我们假设在这个过程中,以GC为对象的堆的大小为HEAP_SIZE. 也就是说在大小为HEAP——SIZE的堆进行内存管理,要花费的时长为(A+B+C).这种情况下,GC的吞吐量为HEAP_SIZE/(A+B+C).
我们都喜欢吞吐量高的GC算法。但是判断各个吞吐量的好坏时不能一概而论。我们比较GC算法和GC标记-清除算法。一般来说,活动对象越少吞吐量越高。而GC算法只检查活动对象,GC标记-清除算法则会检查所有的活动和非活动对象,这个时候GC算法的吞吐量比GC标记-清除算法要高,但是如果活动对象增多,极端情况下,GC标记-清除算法比GC复制算法的吞吐量更高情况。
最大暂停时间
在GC执行的过程中,mutator会暂停执行,如上图所示,最大暂停时间指的是“因执行GC而暂停执行mutator的最长时间”。上图中B的执行时间长,这个时候最大暂停时间是B.
我们在什么情况下要重视最大暂停时间呢? 典型的例子是两足步行机器人,如果在步行过程中启动GC,这个时候对机器的控制就会暂时中断,直到GC执行完毕才能重启,在这个时候,机器人完全不能运作。这个时候,机器人会摔倒。这个时候,我们要使用最大暂停时间短的算法。
堆使用效率
GC算法的不同,堆使用效率也不同。左右堆使用效率的因素有两个。
一个是头的大小,另一个是堆的用法。
在堆中堆放的信息越多,GC的效率也就越高,吞吐量也就改善。这样看来对象的头部越小越好,这样能够存下更多的对象,堆的利用率也高。此外根据堆的用法,堆的使用效率也会出现巨大差异。GC复制算法中将堆二等分,每次只使用一半。相对而言,GC标记-清除算法和引用计数法就能利用整个堆。由于GC是自动内存管理功能,所以过量占用堆就本末倒置了。所以堆使用率也是GC算法的重要评价指标之一。但是很多时候,鱼与熊掌不可兼得,一般来说可用的堆越大,GC运行越快,相反有效地利用有限的堆,GC花费的时间就越长。这看我们的舍取了。
下一篇文章,从标记-清除算法,引用计数算法,GC复制算法一遍遍过这些算法。
发表评论